There are (extremely broadly) 4 key skills to any task: observing the environment, world-modelling, planning next-actions, and executing those actions. This corresponds with the percept/action framework from Russell and Norvig’s Big Book O’ AI Fun: we sense a task environment, then map those senses onto a world-model and determine a future task-solving trajectory, and then act in such a way as to make the task space more the way we want it to be.
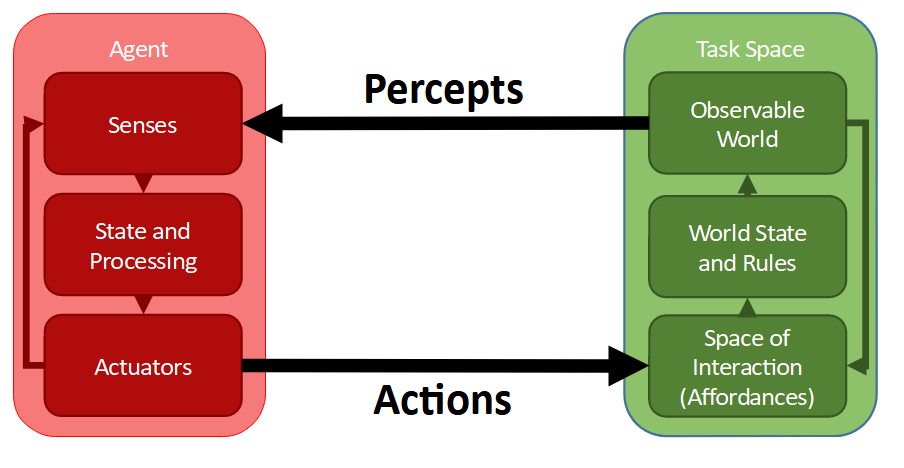
Given this model - how can we maximise task throughput? Disregarding external tools, we’ve only got 3 choices:
- Improve the speed of converting perceptions into a world-model,
- Improve the speed of determining ideal actions from a world-model,
- Improve the speed of actuator execution from action queue.
In the first case, we seek a skill akin to subitising, a skill where rather than interpreting a scene photon-by-photon we rapidly classify into sets of objects. Rather than needing to assess and store “rectangular chunk of wood supported by other rectangular chunks of wood so that the rectangular one stays roughly horizontal” we just say “table” and are done with it. Of course, sometimes these hypersimplifications result in classification errors - ”behold! a man!” - but in practice tend to be a more useful compression of the real world, even when a little lossy. This process of compression is considered by some to be the core component of artificial intelligence.
In the second, you take your compressed world-model and try to determine how to Do The Task. This might be seemingly trivial - for example, if thirsty, picking up a cup and drinking from it. But babies, failing to world-model accurately, may not understand that process would get what they want, and tend to need external assistance. And people with physical disabilities may not have the fine motor control required to grasp the cup or position it near the mouth; they might still solve the task, but need to plan a slower or more cautious chain of actions. To pick a more abstract task example, when trying to win a game of chess, the world-modelling needs to not just be of the present state, but of various possible future states, and choosing which among the available options seems best.
This plan, and the contingencies around it, form an anticipatory action queue; an if-action-then-reaction chain which can result in more rapid responses to anticipated environmental outcomes. An example is a rapid trading of pieces in speed chess, where both players essentially have mutual knowledge of which of their next few moves are “optimal”. This queue allows for a greater degree of automaticity without attention, so the mind can attend to other tasks (additional world-modelling or planning) without needing to prioritise actuation. At higher skill levels, actions can chain together so that minimal unneccessary energy is spent - an activity I refer to as Action Compounding.